年初去 ThoughtWorks 参加道长的镀金玫瑰重构实践里面接触了一个有趣的重构工具–ApprovalTests
不了解这个工具的可以看一下这几个视频:
一句话说明它的好处: 可在没有测试、不懂业务的情况下安全重构
理想的实践
背景
项目初期, 查询完全走数据库, 担心上线后数据库撑不住, 所以想加缓存扛一下. 要加缓存, 就有数据一致性, 那如何保证我加完缓存之前和加缓存之后数据是一致的呢?
解决方案
这个时候就改ApprovalTest出场了.
加缓存前, 得到一份方法输入输出快照, 加缓存后再得到一份方法输入输出快照, 对比快照是否一致, 不一致查原因, 然后想办法让它一致.
开始码
没加缓存之前核心代码是这个样子的 (逻辑不重要, 因为我加缓存的时候也压根没看原逻辑)
List<String> sellerMspuNoList = spuMainArtMapMapper.listMspuNoByGidList(gidList, SpuTypeEnum.toMountedType(SpuTypeEnum.SELLER.getType()));
<select id="listMspuNoByGidList" resultType="string">
select sp.mspu_no as mspu_no from
spu_art_goods_map as art,
spu_main_art_map as sp
where art.aspu_no = sp.aspu_no
and art.record_status = 1
and sp.record_status = 1
and art.gid in
<foreach collection="gidList" item="gid" separator="," open="(" close=")">
#{gid}
</foreach>
and art.mounted_type = #{type}
</select>
依照上面的SQL从数据库中查出尽可能全的样本作为方法输入
运行测试用例
@Test
public void test() {
CombinationApprovals.verifyAllCombinations(
// 要被做成快照的方法
this::foo,
// 为了准备尽可能的测试数据, 我从网上找了一个全组合的算法
// allCombine(1,2,3) = 1,2,3,12,13,23,123
allCombine(Arrays.asList(
"10135729615997",
"13986533400040",
"10074614117237",
"10079230004353",
"10333329717653",
"92345987858551",
"92345284357998",
"92345388758269",
"92345944958270"
)).toArray(new List[]{}),
new Integer[]{1, 2}
);
}
// 要被做成快照的方法
public List<String> foo(List<String> gidList, Integer mountedType) {
return spuMainArtMapMapper.listMspuNoByGidList(gidList, mountedType);
}
得到了一份近千行的方法输入输出快照, 左边是输入, 右边是输出

有了这个就有了重构防护网, 无论如何重构, 结果最终与这个快照一致即可
理想总是美好的
ApprovalTest适合于有返回值的方法, 那么没有返回值的方法怎么做? 找出输入与输出
背景
线上发现一个BUG, 把空集合同步到Redis上了, 定位到方法
/**
* 功能: 刷新SPU缓存,
* 实现: 查库, 塞到Redis里
*/
@Override
public void refreshArtSpuMainSpu(Collection<String> aspuNoList) {
redisUtil.hDel(artSpuMainSpuKey, aspuNoList);
Map<String, List<String>> map = listDbMspuNoByAspuNo(aspuNoList);
List<String> mspuNoList = new ArrayList<>();
map.forEach((aspuNo, list) -> {
mspuNoList.addAll(list);
});
if (CollectionUtils.isEmpty(mspuNoList)) {
return;
}
Map<String, MainSpuMapRedisDTO> mainSpuMap = listDbMainSpuStatus(mspuNoList).stream().collect(Collectors.toMap(MainSpuMapRedisDTO::getMspuNo, mainSpuMapRedisDTO -> mainSpuMapRedisDTO));
Map<String, List<MainSpuMapRedisDTO>> redisMap = new HashMap<>(aspuNoList.size());
map.forEach((aspuNo, list) -> {
List<MainSpuMapRedisDTO> redisList = new ArrayList<>(list.size());
list.forEach(mspuNo -> {
if (mainSpuMap.containsKey(mspuNo)) {
redisList.add(mainSpuMap.get(mspuNo));
}
}
);
redisMap.put(aspuNo, redisList);
});
if (MapUtils.isNotEmpty(redisMap)) {
redisUtil.hMSet(artSpuMainSpuKey, redisMap);
}
}
看了一会之后发现我看不懂, 理解不了其中的意图. 理解不来就不强理解了
找出输入与输出
- 看方法签名, 输入get✔️
public void refreshArtSpuMainSpu(Collection<String> aspuNoList) {
- 方法核心是同步数据到Redis上, 那最后输入到Redis上的数据就是输出, 输出get✔️
if (MapUtils.isNotEmpty(redisMap)) {
redisUtil.hMSet(artSpuMainSpuKey, redisMap);
}
找出尽可能全的测试数据
@Test
public void test() {
CombinationApprovals.verifyAllCombinations(
this::foo,
new MainSpuRedisService[] {
operationRedisService,
sellerRedisService
},
allCombine(Arrays.asList(
"08304580801526034340",
"10271318551717248376",
"19370616753047978750",
"20183344930053283300",
"44483622953739119645",
"52541784473733135239",
"64225367812808144395",
"75705776945714812004",
"87524056439862421934",
"90660551723112007748"
)).toArray(new Set[]{})
);
}
public Map<String, List<MainSpuMapRedisDTO>> foo(MainSpuRedisService service, Collection<String> aspuNoList) {
return service.foo(aspuNoList);
}
如何证明测试数据全面
以 code coverage 运行单元测试即可
再或者这里也可以
运行结束后方法旁边会显示测试用例的覆盖信息
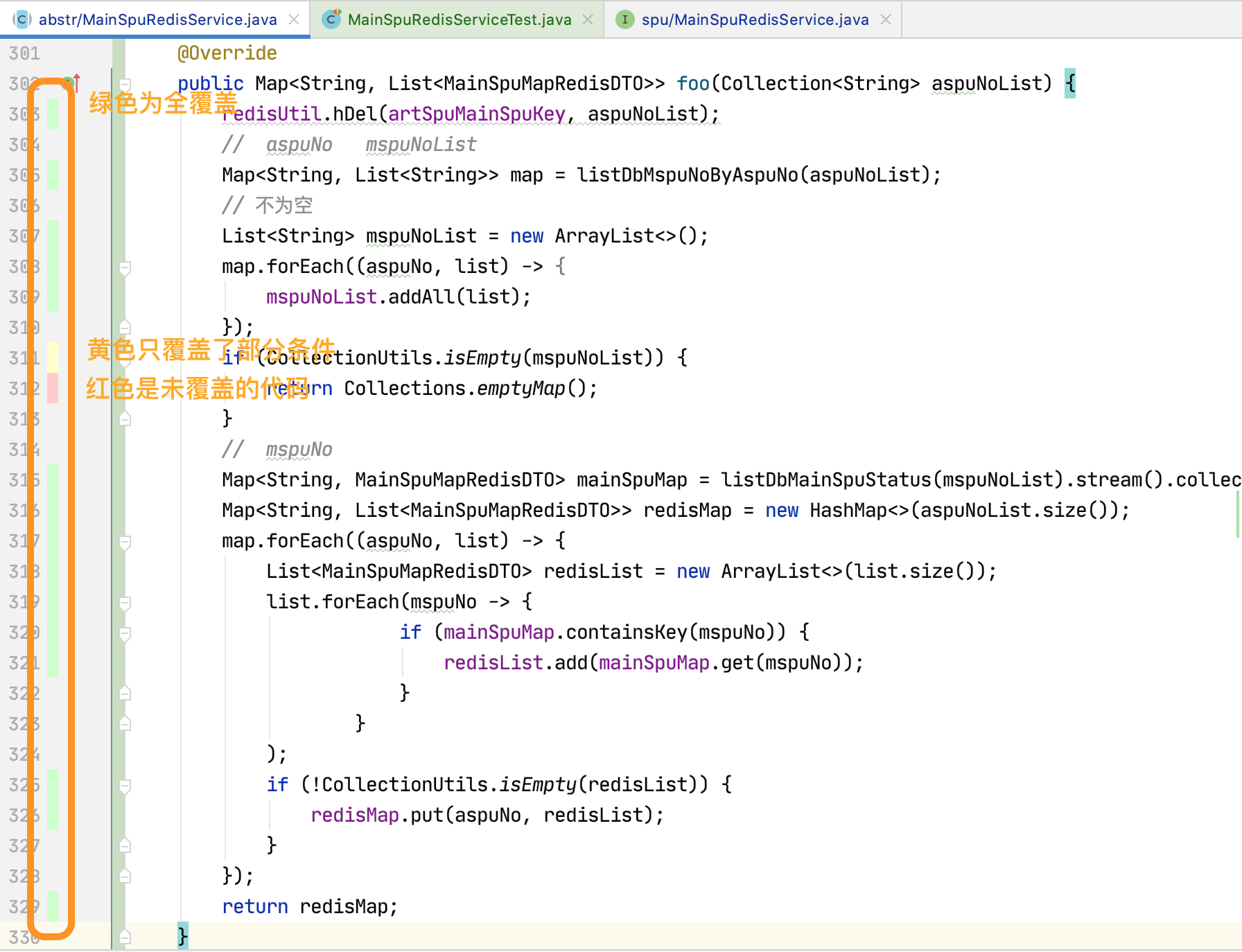
然后调整测试数据把这些全部变为绿色就可以证明测试数据是全面的