接到上游系统报警, 商品服务不可用了.
为什么服务不可用
通过日志排查发现应用抛OOM异常了, 到监控页面进一步确认后证实确实是抛OOM了
线上一共有两台机器, 一台机器OOM了, 一台机器内存完全正常
为了不影响上游服务, 组长重启的OOM的那台机器
为什么OOM
通过日志聚合并没有发现在某个时间段有大量请求
希望能从dump文件中看看有什么问题, 于是开始下载dump文件
由于线上机器的外网带宽很低, 下载也就90k/s, 整个dump文件300M, 下载完成很长时间, 会极大影响排查效率
通知运维人员从内网去下载dump文件, 结果也消耗了2-3个小时才拿到了 dump 文件, 效率非常低, 所以尽可能少拿dump文件
使用 JProfile 打开dump文件

可以直接发现GoodsInfoDO 这个对象占用了2个G的内层, 这并不正常
为什么GoodsInfoDO占用2个G的内存
进一步根据GoodsInfoDO中的属性值来分析对象时如何产生的
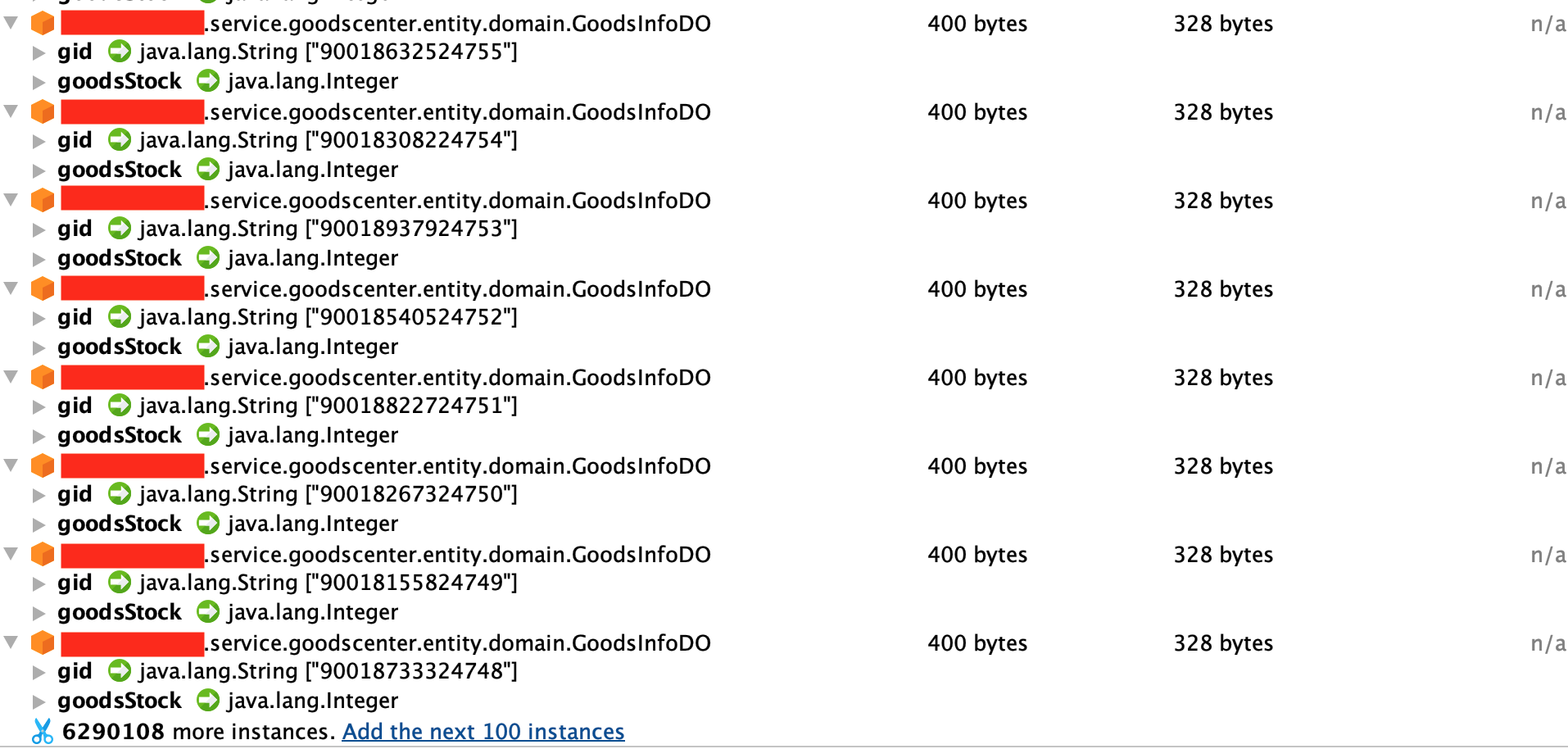
发现对象属性只有gid(商品id)和库存两个属性, DO(Domain Object)尾缀的对象是与数据库存储相关连的对象, 对象来源可能有以下两种情况:
- 服务内部构造出来的将要被写入数据库
- 从数据库中查询出来的
服务中没有批量对库存进行更新业务, 排除第一点可能.
如果是从数据库中查出来的数据, 那这些数据有以下两种来源:
- 从Mapper中查出来的
- 通过MyBatisPlus的
LambdaQueryWrapper查出来的
全局搜索SQL语句, 并没有找到结果
gid, goods_stock
接着全局搜索LambdaQueryWrapper
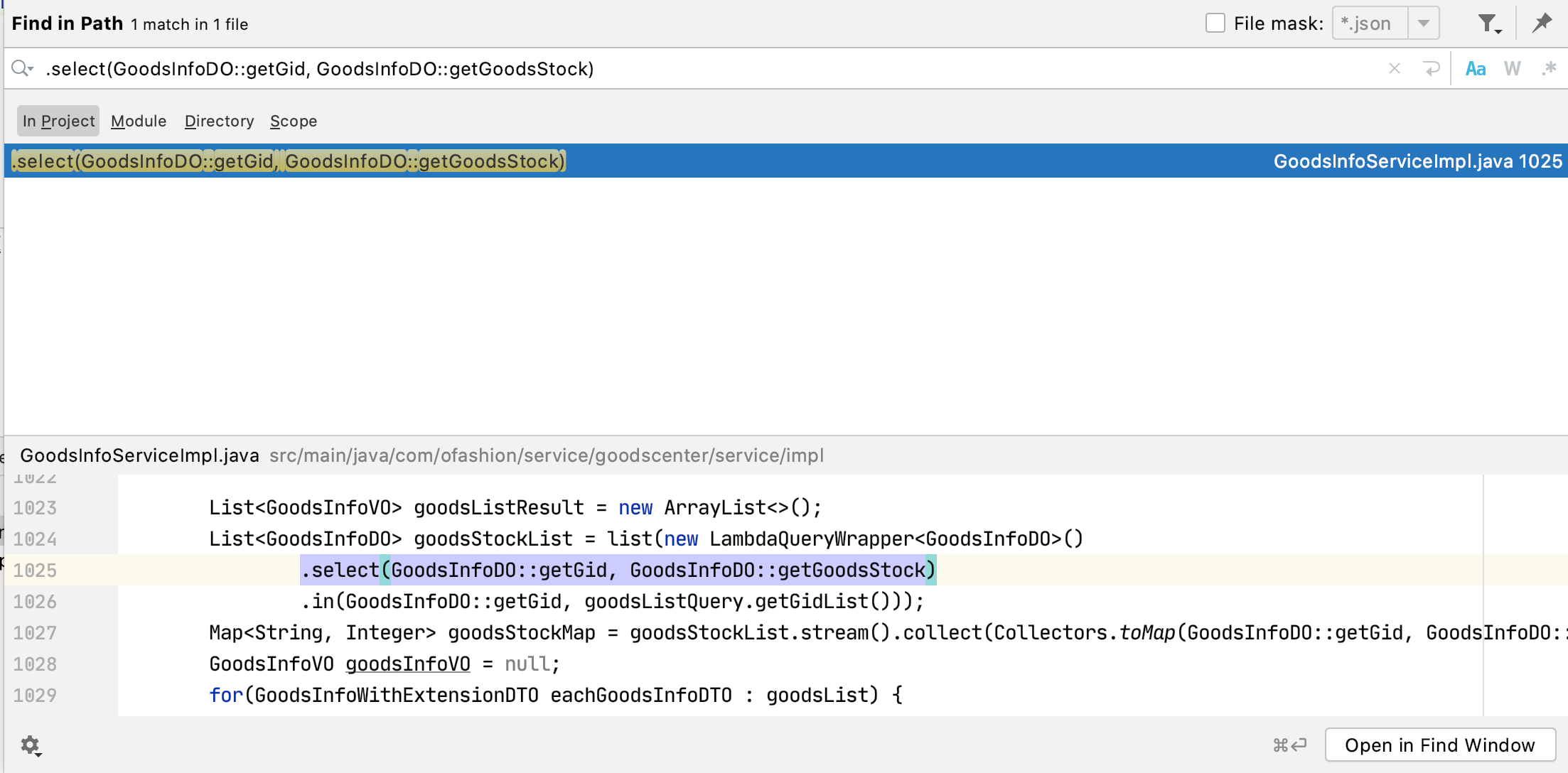
只找到了一处, 初看这个查询并没有什么问题, 但是那2个G的对象肯定是从这里查出来的, 线索中断
回头再看一下对象内容
发现gid(商品id)是连续的, 如果不是恶意请求的话, 那十有八九是查全表了(300万数据)
- 排查是否是恶意请求: 网关日志里是能看到接口请求参数的, 但是在大量请求下如何去找到有问题的请求呢? 当时觉得太麻烦, 直接排查下一个可能了, 现在想想可以用正则匹配出请求体超长的请求
- 排查是否是查全表了
根据之前的线索, 我有一种猜测, 如果 in 的参数传null会不会全表查?
在本地启动服务, POSTMAN 调用了接口, body 传null

查看控制台输出的 SQL 语句

果然是全表搜索了, 于是赶紧修复参数限制, 测试, 上线
反思
为什么会全表查询
因为入参为空时, MyBatisPlus 就不再拼接in的条件, 导致了全表查询
为什么参数可以为空
写代码时忘记加参数校验了, 测试时只测了Happy Path, 没测或者没测到这个异常Path
如何避免以上问题
说实话现阶段的我完全是 By Experience
-
Code Review: 组内曾经组织过一次 Code Review, 但是效果不是很好, 当时我啥业务都不知道, 只能看看 Code Style
-
Test: 组内只有我写测试用例, 其他成员修改了代码后也不跑一下测试用例, 直接找人Review合并. 慢慢的我自己也不维护了, 只在从0到1的开始时写测试用例, 这无疑是一个恶性循环. 这里我需要承认我的写的测试用例并不是很好, 代码稍稍改动, 测试就都挂了, 我近期也在寻找一个写好测试的方法.